Chapter 10 System IO
10.1 Unix I/O¶
一个 Linux 文件就是一个 m 个字节的序列:
在 Linux 系统中, 有着 "Everything is a file" 的设计哲学, 所有的 I/O 设备都被模型化位文件, 所有的输入和输出都当作对相应文件的读和写来进行.
这种将设备优雅地映射成文件的方式, 允许 Linux 内核引出一个简单, 低级的应用接口, 称为 Unix I/O. 这使得所有的输入输出都能以一种统一且一致的方式来执行:
- 打开文件. 应用程序通过要求内核打开相应的文件, 宣告它想访问一个 I/O 设备. 内核返回一个小的非负整数, 叫做 描述符, 他在后续对此文件的所有操作中标识这个文件. 内核记录有关这个打开文件的信息, 应用程序只需要记住描述符.
- Linux shell 创建的每个进程开始时都有三个打开的文件:
- 标准输入(描述符为 0)
- 标准输出 (描述符为 1)
- 标准错误 (描述符为 2)
- 头文件
定义了常量 STDIN_FILENO, STDOUT_FILENO, STDERR_FILIENO 可用来代替显式的描述符值. - 改变当前文件位置. 对于每个文件, 内核保存着一个文件位置 \(k\) , 初始为 0. 这个位置就是相对于文件开头的字节偏移量. 应用程序可以通过执行 seek 操作显式地设置文件位置.
- 读写文件. 一个读操作就是从文件复制 \(n>0\) 个字节到内存, 从文件位置 \(k\) 开始, 如何将 \(k\) 增加到 \(k+n\). 如果读的内容超过文件大小, 会触发 end-of-file(EOF) 的条件.
- 关闭文件. 应用程序完成对文件的访问后, 可以通知内核关闭这个文件. 内核释放文件打开时创建的数据结构, 并将描述符恢复到可用的描述符池. 进程终止时, 内核都会关闭所有打开的文件并释放它们的内存资源
[!note] 使用 lseek 设置文件位置

10.2 文件¶
- 普通文件 (regular file), 通常要区分文本文件和二进制文件. 文本文件是只含 ASCII 或 Unicode 字符的普通文件.
- 目录 (directory)
- 套接字 (socket) 是用来与另一个进程跨网络通信的文件
Windows 与 Linux 的换行差异
在 Windows 系统中, 每一行的结束符为 \r\n, 这是遵循了最早的打字机的习惯, 先回车(光标回到行首, \r), 再换行(光标下移一行\n). 也称为 CRLF.
在 Linux 系统中, 仅使用换行符 \n (ASCII 0xa). 也称为 LF.
这就导致用 Windows 保存文本, 在 Linux 系统下打开, 每一行的末尾都会多出一个 \r, 显示出来是 ^M.
至于在 Linux 下保存的文件在 Windows 系统下打开, 由于现在的编辑器和 IDE 已经非常智能, 它们可以正确识别 Linux 的 LF 换行符, 所以不会有问题. 如果是比较老的编辑器可能会发生所有文本挤在一行的现象.
10.3 打开和关闭文件¶
进程通过调用 open 函数打开一个已存在的文件或创建一个新文件.
| C | |
|---|---|
flags 参数:
- O_RDONLY: 只读
- O_WRONLY: 只写
- O_RDWR: 可读可写
- O_CREAT: 如果文件不存在, 创建一个空文件
- O_TRUNC: 如果文件已经存在, 立即将文件的长度修改为 0
- O_APPEND: 每次写操作设置文件位置到文件的结尾处.
mode 参数:
指定了新文件的访问权限位.
访问权限
访问权限分为可读, 可写, 可执行, 并且需要区分用户(拥有者), 用户组, 其他人的访问权限. 因此可以用 3 个 3 位二进制数来表示.
在 Linux 系统中, 使用 ls -l 命令可以清楚地看到每个文件的访问权限位. 使用 chmod [number] [filename] 将 number 视为一个三位八进制数对文件的权限位进行修改, 例如 chmod 777 就是任何人对这个文件都有读, 写, 执行权限.
作为上下文的一部分, 每个进程都有一个 umask, 通过调用 umask 函数设置. 用带 mode 参数的 open 函数创建一个新文件时, 文件的访问权限位被设置为 mode & ~umask.
文件权限位掩码:
- S_IRUSR
- S_IWUSR
- S_IXUSR
- S_IRGRP
- S_IWGRP
- S_IXGRP
- S_IROTH
- S_IWOTH
- S_IXOTH
对应三种访问者的三种权限.
最后, 进程可以通过调用 close 函数关闭一个已打开的文件.
10.4 读写文件¶
使用 read 和 write 函数来执行输入输出.

在某些情况下, read 和 write 传送的字节比应用程序要求的少, 这些不足值不表示有错误, 出现这种情况的有:
- 遇到 EOF. 第一次读到 EOF 会返回读到的字节数, 此后的 read 将返回 0.
- 从终端读文本行, 一次传送一个文本行, 返回的不足值等于文本行大小
- 读写网络套接字. 由于内部缓冲约束和较长的网络延迟会引起 read 和 write 返回不足值.
10.5 文件元数据¶



10.6 共享文件¶
内核使用三个相关的数据结构来表示打开的文件
- 描述符表 (descriptor table). 每个进程都有独立的描述符表, 它的表项是由进程打开的文件描述符来索引的, 每个打开的描述符表项指向文件表中的一个表项.
- 文件表 (file table). 打开文件的集合, 所有的进程共享这张表. 每个文件表包含当前的文件位置, 引用计数 (有多少个描述符表项指向它), 以及一个指向 v-node 表的指针. 关闭一个描述符会减少相应的文件表表项中的引用计数, 只有引用计数为 0 时内核才会删除这个表项
- v-node 表 (vnode-table). 所有进程共享, 每个表项包含了 stat 结构中的大多数信息, 包括 st_mode, st_size.
理解:
v-node 表相当于文件本体的信息, 文件表相当于文件的一个 copy, 它可以指向文件的不同位置, 描述符表项相当于一个指向文件表的指针, 建立了描述符到文件表的映射. 这样我们就可以把一个描述符看作指向一个文件的 copy.
不同的描述符可能指向同一个文件本体, 但是指向的是不同的文件位置, 好像文件的不同分身一样. 但是这些分身指向共同的 v-node 表, 这是文件的本体信息.
不同的描述符也可以指向同一个文件的分身, 例如通过 fork 操作产生的子进程, 具有和父进程相同的描述符表, 描述符指向的文件表项也相同.



10.7 I/O 重定向¶
Linux shell 提供了 I/O 重定向操作符, 例如:
| Bash | |
|---|---|
可以通过 dup2 函数实现文件的重定向.

dup2 函数复制描述符表表项 oldfd 到描述符表表项 newfd, 覆盖 newfd 以前的内容. 如果 newfd 原来指向的文件分身引用计数变成 0 了, 内核就会回收它.
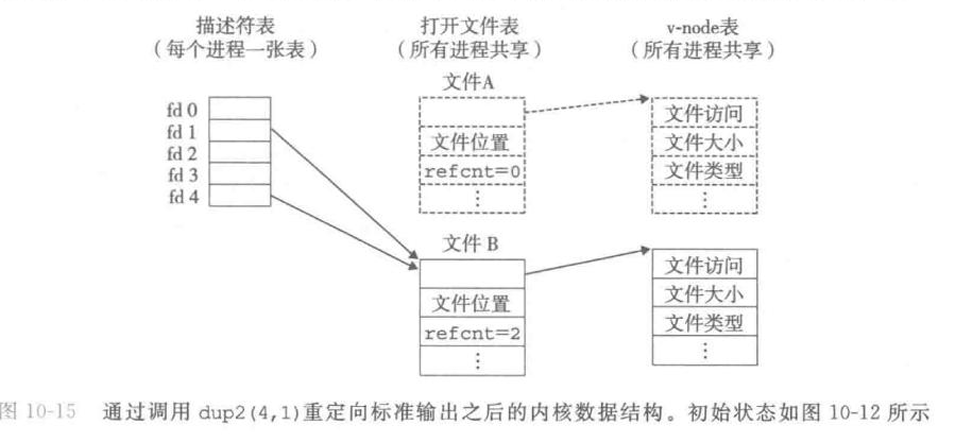
这样我们就把 fd1 对应打开的文件变成 fd4 对应打开的文件.
10.8 标准 I/O¶
C 语言定义了一组高级输入输出函数,称为标准 I/O 库,为程序员提供了 UnixI/O 的较高级别的替代。这个库 (libc) 提供了打开和关闭文件的函数 (fopen 和 fclose) 、读和写字节的函数(fread 和 fwrite)、读和写字符串的函数(fgets 和 fputs),以及复杂的格式化的 I/O 函数(scanf 和 printf).
标准 I/O 库将一个打开的文件模型化为一个流。对于程序员而言,一个流就是一个指向 FILE 类型的结构的指针。每个 ANSI C 程序开始时都有三个打开的流 stdin、stdout 和 stderr,分别对应于标准输人、标准输出和标准错误:

缓冲区的目的就是使开销较高的 Linux I/O 系统调用的数量尽可能小, 例如, 读的时候, 库会通过调用一次 read 函数来填充缓冲区, 接下来的读操作都可以在缓冲区进行. 写的时候, 不会立即调用 write, 而是等缓冲区填满了或者遇到某些条件之后再调用 write.

标准 IO 流与文件的连接
stdio 流(FILE *)是对底层文件描述符(int fd)的封装,主要目的是为了实现缓冲(Buffering)。
- 打开文件: 当你使用
fopen("data.txt", "r")时,fopen在底层实际上会调用open("data.txt", O_RDONLY),获取一个文件描述符(例如 \(FD=3\))。 -
创建流:
fopen会创建一个FILE结构体,这个结构体内部存储着: -
该文件的文件描述符(\(FD=3\))。
- 一个用于读/写优化的内存缓冲区。
-
当前流的位置、模式等状态信息。
-
读写操作: 当你调用
fscanf(fp, ...)时,C 库会先尝试从内存缓冲区中读取数据。如果缓冲区空了,C 库会使用底层的read(3, ...)系统调用一次性读取一大块数据到缓冲区,然后再提供给fscanf。
写入文件和写入终端的缓冲方式
对于磁盘文件, stdio 默认采用全缓冲模式, 即遇到缓冲区写满, 显式调用 fflush(), 正常退出或关闭文件时才会刷新缓冲区
对于写入到终端, 默认采用行缓冲模式, 遇到换行符也会刷新缓冲区.
Buffer Quiz
这段代码在终端一共输出几个 "-" 字符?
(如果是输出到文件, 一共输出几个 "-" 字符?)
(如果增加 \n, 打印到文件和终端分别一共输出几个 "-" 字符?)
10.9 RIO 的带缓冲的输入函数¶
RIO 是一种健壮的 I/O 包, 它会自动处理不足值. 在像网络程序这样容易出现不足值的应用中, RIO 提供了方便, 健壮和高效的 I/O 函数. RIO 提供两类不同的函数:
- 无缓冲的输入输出函数. 这些函数直接在内存和文件之间传递数据, 没有应用级缓冲.
- 带缓冲的输入函数. 这些函数高效地从文件中读取文本行和二进制数据, 文件的内容缓存在应用级缓冲区内. 带缓冲的 RIO 输入函数是线程安全的, 它在同一个描述符上可以被交错地调用.
10.9.1 RIO 的无缓冲的输入输出函数¶


通过这种方式, 我们解决了 read 被信号中断读入不足值的问题. (如果 read 在读入部分数据后被中断, 会返回已经读到的字节数. 如果在读入前被中断, 会返回 EINTR)
10.9.2 RIO 的带缓冲的输入函数¶

每打开一个描述符, 就要调用一次 rio_readinitb 函数, 它将描述符 fd 和地址 rp 处的一个类型为 rio_t 的读缓冲区联系起来.
rio_readlineb 从缓冲区 rp 中读出下一个文本行, 将它复制到内存位置 usrbuf, 并用 NULL 字符结束这个文本行. 因此 rio_readlineb 最多读 maxlen-1 个字节, 超过 maxlen-1 的文本行会被截断.
对同一描述符, rio_readlineb 和 rio_readnb 可以交叉进行. 然而带缓冲的函数调用却不应和无缓冲的 rio_readn 交叉使用. (如果交叉使用, 无缓冲会从缓冲区结束后的下一个字符开始读, 而不是缓冲区内的下一个字符, 导致错位.)

RIO 读程序的核心是 rio_read 函数, 它是 Linux read 函数的带缓冲版本. 当调用 rio_read 要求读 n 个字节时, 假设都缓冲区内有 rp->rio_cnt 个未读字节. 如果缓冲区为空, 那么会通过调用 read 填满它. 一旦非空, rio_read 从读缓冲区复制 min(n, rp->rio_cnt) 个字节到用户缓冲区, 并返回复制的字节数.


总结:
- read 会被信号终止, 如果终止的时候还未读任何数据返回 -1 并设置 errno, 如果终止的时候已经读了部分字节会返回读到的字节数, 无缓冲区
- rio_read 会被信号终止, 如果终止的时候还未读任何数据会重新尝试, 如果终止的时候已经读了部分字节会返回读到的字节数, 有缓冲区
- rio_readn 无缓冲区, 利用 read 实现.
- rio_writen 无缓冲区, 利用 write 实现.
- rio_readnb 有缓冲区, 利用 rio_read 实现.
- rio_readlineb 有缓冲区, 利用 rio_read 实现.
10.10 如何使用 I/O 函数¶


- 只要有可能就使用标准 I/O
- 不要用 scanf 或 rio_readlineb 读二进制文件.
- 对 socket 的 I/O 使用 RIO 函数.
socket
全双工通信:同一个 socket 描述符可同时读写数据。
无文件偏移指针:读写操作独立,不影响对方数据流。
缓冲机制:内核维护接收和发送缓冲区,数据通过缓冲区传输
因此, 内核对一个 socket 只会有一个描述符.
为什么网络编程不宜使用 Standard I/O
对于跟在输出函数之后的输入函数, 由于套接字使用 lseek 函数是非法的(它根本没有偏移, 是流式的, 过去的不能再回来), 因此只能使用 fflush 刷新缓存区.
对于跟在输入函数之后的输出函数, 没有办法刷新缓存区. 除非输入函数遇到了文件结束.
因此, 我们要对同一个打开的套接字描述符打开两个流, 一个用于读, 一个用于写. 但是他要求应用程序在两个流上都调用 fclose, 这些操作中的每一个都试图关闭同一个底层的套接字描述符, 所以第二个 close 会失败. 在一个线程化的程序关闭一个已经关闭了的描述符会导致灾难. (见 12.7.4 节)
RIO 因为只有读入有缓存区, 而写入没有缓存区, 所以不会互相影响.
在同一个缓存区上输入输出会发生什么
如果标准输入输出共享一个缓存区, 那么:
如果在输入函数之后没有刷新缓存区, 输出函数会将输入函数未读的部分也打印出来
先写后读, 如果没有刷新缓存区, 读入会读入写到缓存区的内容
From Gemini
既然读和写是不同的操作,为什么 Standard I/O (stdio) 不要求您为读操作打开一个文件流,同时为写操作打开另一个文件流,而是允许您使用像 r+ 这样的模式共用一个流。
这种设计背后是效率、方便性和原子性的权衡。
1. ⚙️ 效率和方便性:避免不必要的系统调用¶
-
单一文件描述符: 在操作系统的底层,无论是读还是写,共用一个流意味着只需要一个文件描述符 (FD)。
-
文件指针共享: 读写共用一个流时,它们共享同一个文件指针 (File Position Indicator)。这在需要频繁切换读写方向的应用中非常高效:
-
场景: 数据库或索引文件。您可能需要先读取文件头部(读操作),然后移动文件指针到某个特定位置(
fseek),再更新该位置的数据(写操作),然后立即再读取附近的数据。 -
优势: 如果您必须创建两个流,每次切换读写时,您需要协调和同步两个独立文件流的指针,这会复杂化编程,并可能增加系统开销。共用一个流确保了读写操作始终作用于文件的同一个精确位置。
-
2. 🛡️ 简化并发控制 (原子性)¶
如果一个进程对同一个文件打开了两个独立的流(一个读流、一个写流),那么操作系统内核就必须确保对这两个流的操作不会互相干扰,这引入了复杂的同步问题。
- 单一锁机制: 当使用一个共用流时,stdio 库只需要管理一个内部缓冲区和一个文件指针。在进行读写切换时的刷新操作 (
fflush或fseek) 本质上就是一种同步点,确保了操作的顺序性和原子性,简化了库内部的复杂性。
3. ⚖️ 权衡:读写切换的额外要求¶
正是因为共用了一个流,才需要引入我们之前讨论的约束:
-
约束: 在读操作和写操作之间切换时,您必须调用
fflush()或fseek()等函数。 -
理由: 这是因为 stdio 库为了效率默认启用了内部缓冲区。如果不刷新或重定位指针,您可能会遇到以下问题:
-
写后读: 您写入的数据可能还停留在输出缓冲区中,没有真正写入磁盘,此时去读取文件,就会读不到刚刚写入的内容。
-
读后写: 您读取文件后,输入缓冲区中可能还有多余的数据,此时直接写入可能会破坏文件指针的位置,或导致写入的数据被错误地覆盖。
-

- 为什么 Standard I/O 不是异步信号安全, RIO 是异步信号安全?
Note
Standard I/O 的 printf 函数共用一个缓存区, 在执行的时候会加锁避免缓存区被其他的函数更改. 如果加锁后立刻被信号处理程序中断, 且信号处理程序中又使用了一次 printf, 那么这个 printf 就会陷入死锁状态(前一个还没解锁)
RIO 没有锁的机制, 如果程序和信号处理程序的 buffer read 指向同一个缓存区会发生交叉读入现象.