Chapter 08 内排序
8.0 排序的分类¶
- 内部排序: 在内存进行的排序
- 外部排序: 排序过程需要访问外存
8.1 基本概念¶
- 记录: 进行排序的基本单位
- 关键码: 唯一确定的一个或多个域
- 排序码: 作为排序依据的一个或多个域
- 序列: 线性表, 由记录组成的集合
- 排序: 将序列中的记录按照排序码特定的顺序排列起来
稳定性: 对于任意两个有相同排序码的记录, 排序后相对次序不变
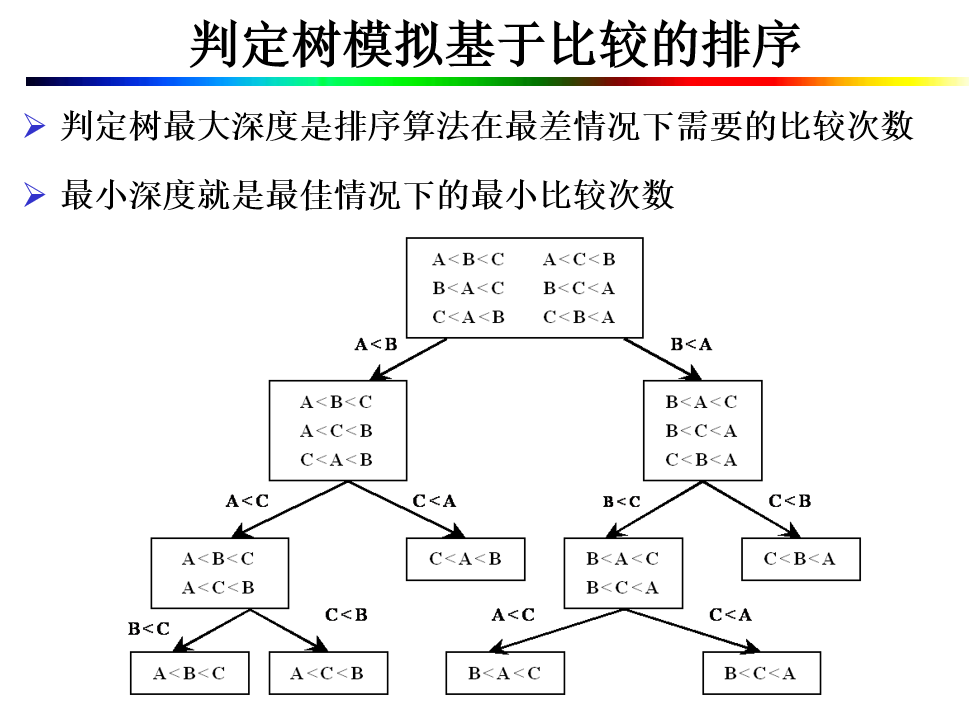
8.2 三种 O(n^2) 的简单排序¶
8.2.1 插入排序¶
算法: 依次将每个待排序的记录插入到一个有序子文件的合适位置.
代码:
| C++ | |
|---|---|
稳定性: 稳定的, 相对位置不会改变
空间代价: \(O(1)\)
时间代价:
- 最佳情况: 正序, \(n-1\) 次比较, \(0\) 次交换, 复杂度 \(\Theta(n)\)
- 最坏情况: 逆序, 比较和交换次数为 \(n(n-1)/2\)
- 平均情况: \(O(n^2)\)
优化的插入排序: 不用每次比较都交换, 保存最后要交换的位置.
基于二分查找的插入排序: 利用好已插入的集合的有序性, 比较次数降为 \(O(n\log n)\), 移动次数仍为 \(n^2\) 级别. 最佳情况时间代价: \(\Theta(n\log n)\), 最差和平均情况 \(\Theta(n^2)\)
8.2.2 冒泡排序¶
算法: 不停比较相邻记录, 如果不满足就交换相邻记录, 直到所有的记录都已排好序. 最大值(最小值)就好像冒气泡一样一步步来到序列最后(最前)
代码:
| C++ | |
|---|---|
稳定性: 稳定的
空间代价: \(O(1)\)
时间代价: 比较次数 \(n(n-1)/2\), 交换次数最多为 \(\Theta(n^2)\), 最小为 \(0\), 最大, 最小,平均时间代价均为 \(\Theta(n^2)\)
优化的冒泡排序: 如果一次冒泡过程没有任何交换直接停止, 最小时间代价为 \(\Theta(n)\)
8.2.3 直接选择排序¶
算法: 每一趟从后面 \(n-i\) 个待排记录的最小值和第 \(i\) 个记录交换
代码:
| C++ | |
|---|---|
稳定性: 不稳定的, 由于直接选择排序每次是直接和后面的最小值交换, 所以可能把相对位置在前面的记录换到后面.
最差最好平均时间代价与比较次数均为 \(\Theta(n^2)\)
8.3 Shell 排序¶
Shell 排序基于直接插入排序的 2 个性质
- 待排序序列较短情形下效率高
- 整体有序的情形下时间代价低


代码:
| C++ | |
|---|---|
稳定性: 划分为子序列的时候可能把相对位置靠前的记录交换到后面, 因此是不稳定的.

8.4 基于分治的排序¶
8.4.1 快速排序¶

轴值选择要尽可能让 \(L\) 和 \(R\) 长度相等, 可以固定位置, 中值计算, 随机选择.
序列划分:
选择首元素为轴值. 用两个指针不断将大于 pivot 的放到后面, 小于 pivot 的放到前面.

稳定性: 划分的时候可能把相对位置靠前的记录放到后面, 因此是不稳定的.
时间代价: 最佳: \(O(n\log n)\) (每次均匀划分) 最差 \(O(n^2)\) (每次划分为 1 个和剩余的)
平均性能:
假设 \(\text{pivot}\) 的选取是随机的
$$
\begin{align}
T(n)&=\frac{1}{n}\sum_{i=0}^{n-1}(T(i)+T(n-i-1))+cn \
&=\frac{2}{n}\sum_{i=0}^{n-1}T(i)+cn\
nT(n)&=2\sum_{i=0}{n-1}T(i)+cn2\
nT(n)&-(n-1)T(n-1)=2T(n-1)+2cn-c\
nT(n)&=(n+1)T(n-1)+2cn\
\frac{T(n)}{n+1}&=\frac{T(n-1)}{n}+\frac{2c}{n+1}\
\frac{T(n)}{n+1}&=2c(\frac{1}{n+1}+\frac{1}{n}+...+\frac{1}{3})=2c\log(n)\
T(n)&=O(n\log n)
\end{align}
$$
8.4.2 归并排序¶
稳定的 \(O(n\log n)\) 算法. 存储开销较大
8.5 堆排序¶
对所有记录建立最大堆 \(O(n)\)
取出堆顶记录与数组末端交换, 重新调整堆.
稳定性: 类似直接选择排序, 每次将最大值与末尾交换, 稳定性无法保证.
8.6 分配排序¶
8.6.1 桶排序¶
将记录的排序字存到桶里, 记录 count[i]=count[i-1]+count[i] 表示小于等于 i 的记录数量, 收集从后往前保持稳定性.
空间与时间代价: 均为 \(\Theta(m+n)\)
8.6.2 基数排序¶
将排序码分为 \(d\) 位子排序码, 子排序码的取值范围称为基数, 记作 \(r\)
例如, 一般的整数排序可以看作十进制的每一位为子排序码, 基数为 \(10\)
高位优先法: 先按最高位桶排序, 再按次高位...

低位优先法: 从最低位往上排序.

空间代价: \(\Theta(n+r)\) 临时数组 + \(r\) 个计数器
时间代价: \(\Theta(d\cdot (n+r))\)
基于静态链的基数排序:
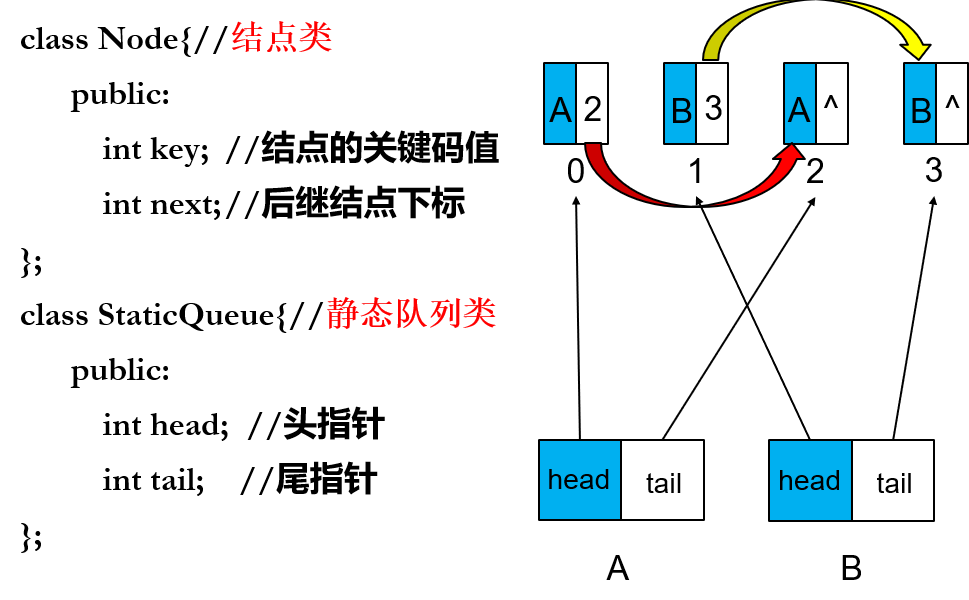
利用链表把几个桶连起来, 在排序的时候避免大量复制操作
分: 将所有桶头指针清空, 遍历 Array 将元素加入每个桶的链表尾部.
合: 先找到第一个非空的桶把 Array 的起始设置为该桶的头, 此时结尾就是该桶的尾, 接下来继续找非空的桶, 把 Array 结尾的 next 指针指向桶的头, 就可以把不同的桶串联起来.

8.6.3 索引排序¶
移动记录时只移动索引, 不移动记录本身, 减少记录移动次数开销.
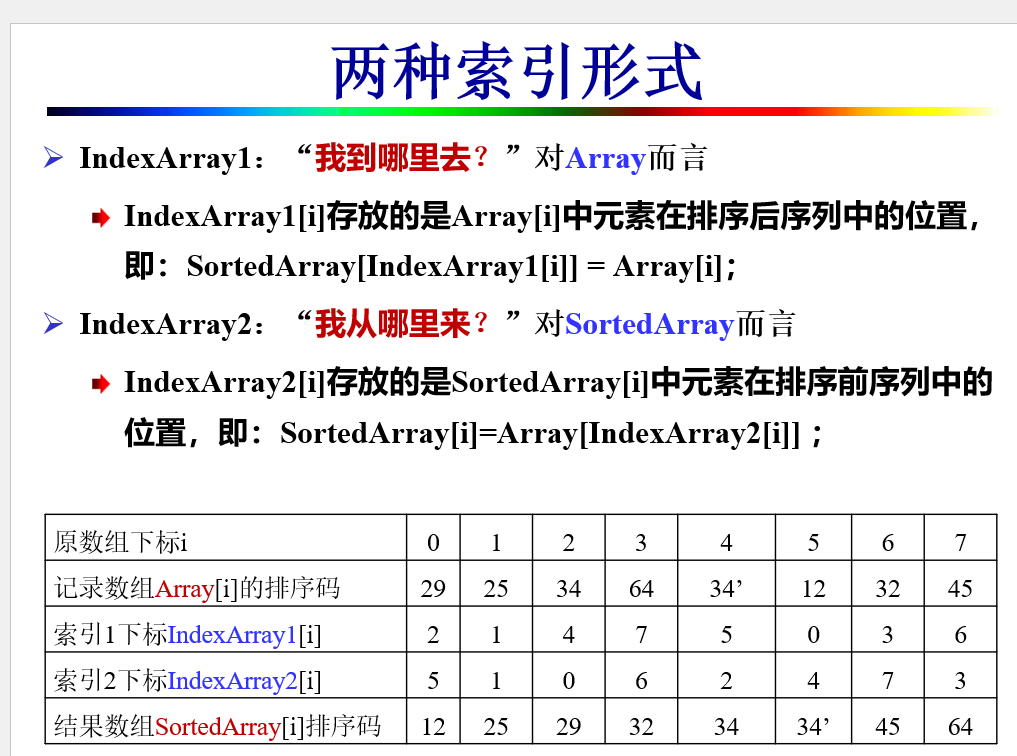
下面以 Index2 为例.
将索引看成一个个环
由于索引需要满足:
因此
$$
\begin{align}
| Text Only | |
|---|---|
1 2 3 4 | |
\end{align}
$$
先把 \(\text{Array}[i_0]\) 保存了就可以一直把后面的值赋给前面, 最后把保存的值赋给环上最后一个元素.
8.7 各种排序算法比较¶
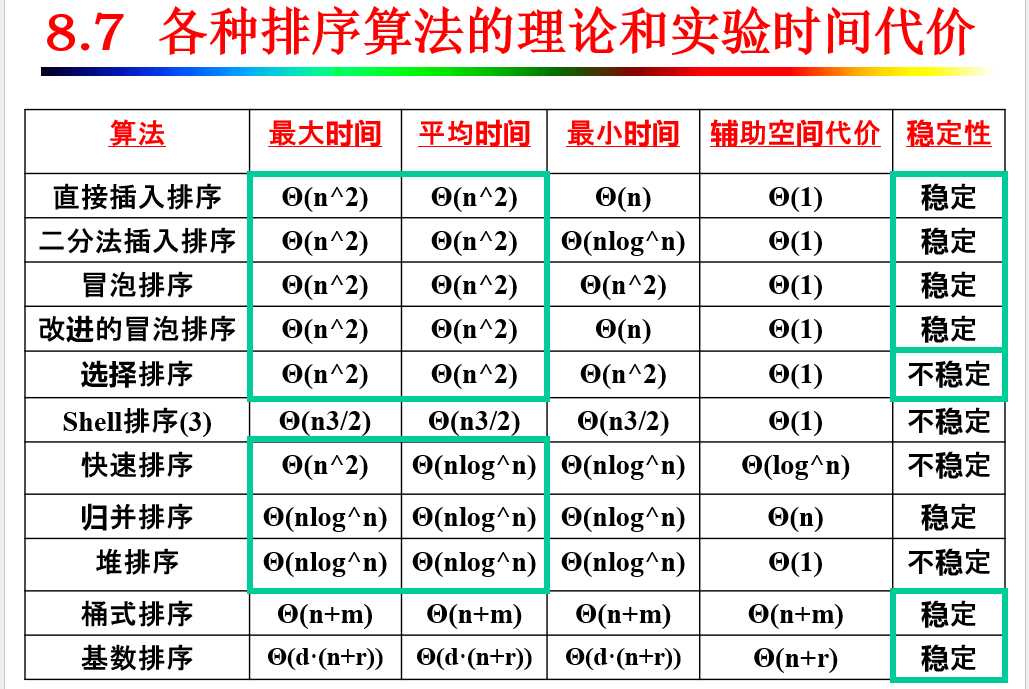
不适合使用链式存储的排序算法: 即需要支持随机下标访问, 如上表中的二分法插入排序, Shell 排序, 堆排序.
特别地, 归并排序使用链表实现可以避免辅助数组的使用, 降低空间开销和复制开销.
8.8 排序问题的界¶