Chapter 06 Cache
6.1 存储技术¶
6.1.1 随机访问存储器 (RAM)¶
- 静态 RAM: SRAM 常用来制作高速缓存, 速度快, 持续
- 动态 RAM: DRAM 常用来制作主存, 帧缓冲区, 速度较慢, 不持续, 需要刷新
- 传统的 DRAM:
- DRAM芯片中有 d 个超单元, 每个超单元由 w 个 DRAM 单元组成, 可存储 dw 位信息
- 通过 addr 引脚先传送行, 再传送列, 通过 data 引脚传送数据
- 内存模块: 有多个 DRAM 芯片组成, 每个储存主存的一个字节.\
- 增强的 DRAM:
- 快页模式 DRAM: 对同一行连续的访问可以直接利用行缓冲区
- ...
- 非易失性存储器: 断电后仍然保存信息
- PROM: 只能编程一次
- 可擦写可编程 ROM: 通过光编程, 1000次
- 电子可擦除 PROM: 可在电路卡上直接变成, 10^5 次
- 闪存
- 连接系统总线和内存总线: I/O桥
6.1.2 磁盘¶
由盘片构成, 每个盘片有两面(称为表面), 中央是主轴.
每个表面由一组磁道的同心圆组成, 每个磁道被划分为一组扇区, 扇区之间有一些间隙.
访问时间 = 寻道时间 + 平均旋转时间(1/2最大旋转时间) + 读取一个扇区的时间(最大旋转时间/平均扇区数)
逻辑块: 给每个扇区的编号
不需要 CPU 干涉而可以自己执行读或者写总线事物称为 DMA (直接内存访问), 在传送结束后一般会发送一个中断信号通知 CPU.
6.1.3 固态硬盘¶
读 SSD 比些要快. 只有在一页所属的块整个被擦除后, 才能写这一页.
随机写很慢:
- 擦除很耗时
- 如果试图修改一个已经有数据的页, 这个块中的所有有用数据的页都必须复制到一个新的擦除过的块.
6.2 局部性¶
- 时间局部性: 被引用过一次的内存位置在不远的将来再被多次引用
- 空间局部性: 一个内存位置被引用了, 它附近的内存位置在不远的将来被引用
6.3 存储器层次结构¶

6.3.1 存储器层次结构中的缓存¶
中心思想: 对于每个k, 位于 k 层的更快更小的存储设备作为位于 k+1 层的更大更慢的存储设备的缓存.
- 缓存命中: 需要 k+1 层的数据时刚好在第 k 层找到
- 缓存不命中: 第 k 层需要从 第 k+1 层取出包含 d 的块, 如果第 k 层的缓存满了, 需要驱逐现存的一个块. (LRU驱逐策略, 替换掉最后被访问的时间距现在最远的块)
- 冷不命中: 由于缓存为空导致
- 冲突不命中: 缓存还没满, 但是下一层要存放到的块是有限制的, 而这些块满了. (比如下一层编号为 i 的块只能存放到 i % 4 的块)
- 容量不命中: 缓存太小了, 已经满了
6.4 高速缓存存储器¶
由于 CPU 和主存之间逐渐增大的差距而在 CPU 寄存器文件和主存之间插入的 SRAM 高速缓存存储器. L1, L2 高速缓存, 有的还有 L3 高速缓存.
6.4.1 通用的高速缓存存储器组织结构¶
假设地址有 m 位, 有 2^m 个不同地址.
- S=2^s: 有 S 个高速缓存组
- E: 高速缓存行
- B=2^b: 数据块
- 1位有效位
- m-s-b个标记位
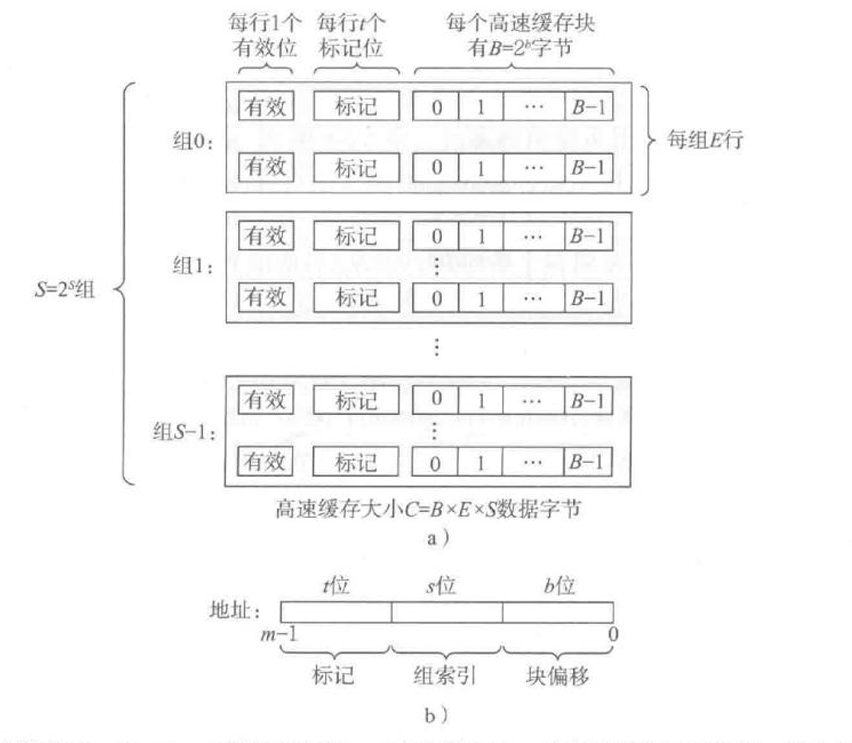
高速缓存的容量: S*E*B
本质上就是把一些连续的数据(B字节)看作一个集合, 然后一共可以存放 S*E 个集合
集合用(标记位,组号)来确定, 如果每个组有多行就可以存放多个集合, 否则只能每个组只能存放一个集合(E=1)
快速确定组号: (地址 / B) % S
标记位: 地址 / (B * S)
查找速度: 直接映射>组相联>全相联 (后面两个要匹配每一行)
命中效率: 直接映射<组相联<全相联 (全相联所有位置都可以放, 直到缓存满, 直接映射有可能缓存没满就要驱逐)
因此, 全相联更多用在很小的缓存, 如 TLB 中.
6.4.2 高速缓存的写¶
首先区分两种情况, 写命中和写不命中. 写命中就是要写的数据在这一层高速缓存中
写命中: 这时候我们可以直接更改这一层的数据, 然后要思考怎么更改低一层的数据.
- 直写: 立即将 w 的高速缓存块写会到紧接着的低一层, 虽然简单, 但是每次写都会引起总线流量.
- 写回: 推迟更新, 只有当替换算法要驱逐这个更新过的块时, 才把它写到下一层. (有点类似线段树的懒标记), 缺点是需要额外维护修改位
写不命中:
- 写分配: 加载低一层的块到高速缓存中, 然后更新. 它试图利用写的空间局部性(相邻的位置可能也会被写), 但是每次不命中都要传送一个块.
- 非写分配: 避开高速缓存, 直接写到低一层中(不命中就不命中吧, 不管了)
观察一下, 怎么判断某层的高速缓存是采用哪种策略. 首先对于比较低层的缓存, 由于传送时间很慢, 每次写都要花费时间很久, 所以我们一般采用写命中时写回+写不命中时写分配. 反之对于高层的缓存, 传送时间比较快, 我们一般采用写命中时直写+写不命中时非写分配. 当然这也不是绝对的, 现在写回的高复杂性不再是阻碍, 因此几乎所有层次都能看到写回缓存.
但是无论怎样, 写回+写分配, 直写+非写分配的组合一般是配套出现的, 因为它们的理念是一样的, 一个是利用局部性, 一个是立刻写到下一层.
6.4.3 真实的高速缓存层次结构解剖¶
只保存指令的高速缓存称为 i-cache, 只保存数据的高速缓存称为 d-cache.
6.4.4 高速缓存性能影响¶
- 不命中率: 不命中数量/引用数量
- 命中率:
- 命中时间:
- 不命中处罚: 不命中所需要的 额外时间
6.5 存储器山¶
通过预热和真正循环体现时间局部性(空间越大, 访问的时间间隔就越长), 通过步长体现空间局部性
在步长为 1 时, Core i7 会有硬件预取机制优化, 导致工作集即使超出了 L1, L2 Cache 的大小, 也能达到 12GB/s 的吞吐量.