Chapter 10 检索
10.0 基本概念¶
检索:
- 在记录集合中找到 "关键码值=给定值" 的记录
- 或找到关键码值 "符合特定约束条件" 的记录集
平均检索长度:
- 检索过程中对关键码的平均比较次数
\(P_i\) 是检索第 \(i\) 个元素的概率, \(C_i\) 是找到第 \(i\) 个元素所需的比较次数.

提高检索效率的方法:
- 预排序
- 建立索引
- 散列技术
检索算法分类:
- 基于线性表的检索: 顺序检索, 二分检索
- 根据关键码值直接访问: 根据数组下标直接检索
- 树索引: 二叉搜索树, B 树
- 基于属性的检索: 倒排索引
10.1 基于线性表的检索¶
10.1.1 顺序检索¶
假设序列为 \(a_1,...,a_n\), 将 \(a_0\) 设置为待检索值, 倒序检查.
性能分析:
检索成功: \(\frac{n+1}{2}\)
检索失败: \(n+1\)


10.1.2 二分检索¶
前提: 待检索序列有序
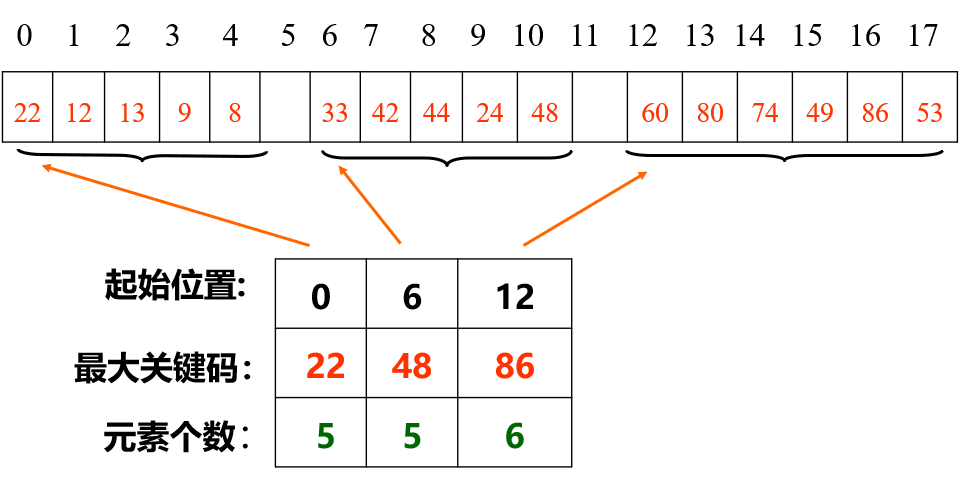
10.1.3 分块检索¶
按块有序, 块内无序, 块间有序(前块最大关键码<后块最小关键码)





10.2 散列表的检索¶
基本思想: 根据确定的散列函数 \(h\) 和关键码 \(k\) 计算存储位置 \(h(k)\)
10.2.1 重要概念¶
- 负载因子 \(\alpha=n/M\), \(n\) 是散列表已有结点数, \(M\) 是散列表空间大小
- 冲突: 将不同的关键码映射到相同的散列地址
- 同义词: 发生冲突的两个关键码.
- 散列函数: \(h: K\to [0,M-1]\)
10.2.2 散列函数¶
1. 除余法
通常选择质数, 增加均匀分布的可能性.
连续的关键码映射到连续的数组单元, 可能导致散列性能降低.
2. 乘余取整法
此处 \(\{\cdot\}\) 代表取小数部分

3. 平方取中法

4. 数字分析法
- 对 \(n\) 个 \(d\) 位数, 每一位可能有 \(r\) 种不同的符号, 在各位上出现频率不一定相同. 可根据散列表大小, 选取期中分布均匀的若干位作为地址.
- 这一方法完全依赖于关键码集合的性质
各位数字中符号分布的均匀度 \(\lambda_k\)
$\(\lambda_k = \sum_{i=1}^r(\alpha_i^k - n/r)^2\)$
- \(\alpha_i^k\) : 第 \(i\) 个符号在第 \(k\) 位上出现的次数
- \(n/r\) : 各种符号在 \(n\) 个数中均匀出现的期望值
- \(\lambda_k\) 越小, 说明越均匀
5. 基数转换法
将关键码看成另一进制数再转换回原来进制上的数
6. 折叠法


10.2.3 冲突的解决方法¶
- 开散列方法: 也称拉链法, 所有同义词链接在同一链表, \(\alpha\) 可以大于 1
- 闭散列方法: 也称开地址法, 把发生冲突的关键码存储在散列表中另一个空地址内
10.2.4 开散列¶
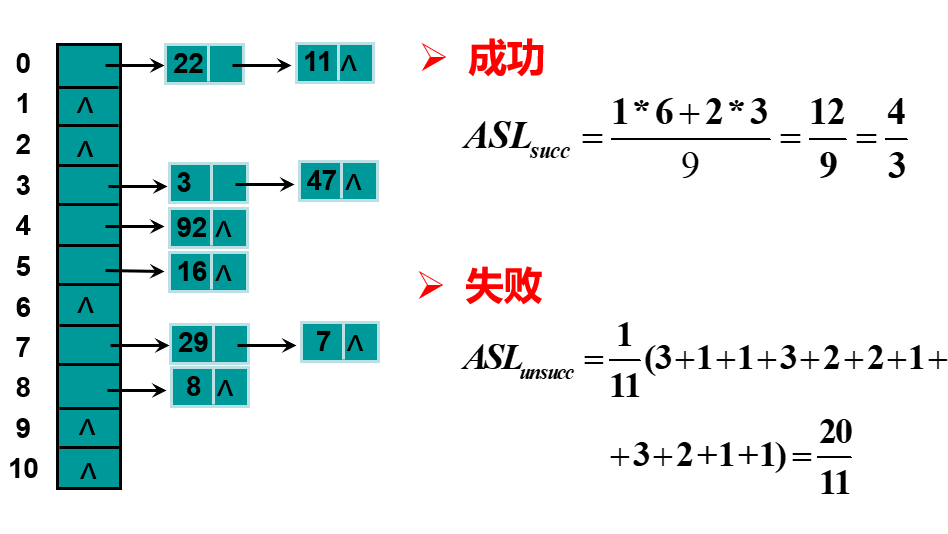
A. 拉链法


ASL 计算: 认为与 NULL 比较也是一次比较


B. 桶式散列
相当于为冲突元素开辟了一段连续空间, 这样冲突的时候检索就可以在连续的地址空间做, 避免像链式散列一样地址不连续导致多次访问外存.
10.2.5 闭散列方法¶
- \(d_0=h(K)\) 称为 \(K\) 的基地址
- 当冲突发生时, 用某种方法为 \(K\) 生成一个候选的散列地址序列, 称为探查序列:
$$
d_1,d_2,...,d_i,...d_{M-1}
$$ - \(d_i=d_0+p(K,i)\) 是后继散列地址, \(p\) 是探查函数
插入 \(K\) 时, 若基地址被占用, 按照探查序列依次查找第一个空闲位置, 若所有位置都不空闲, 说明闭散列表已满, 报告溢出.
1. 线性探查
探查序列: \(d_0+1,d_0+2,...,M-1,0,1,...,d_0-1\)
产生聚集问题, 可能导致很长的探查序列, 示例:
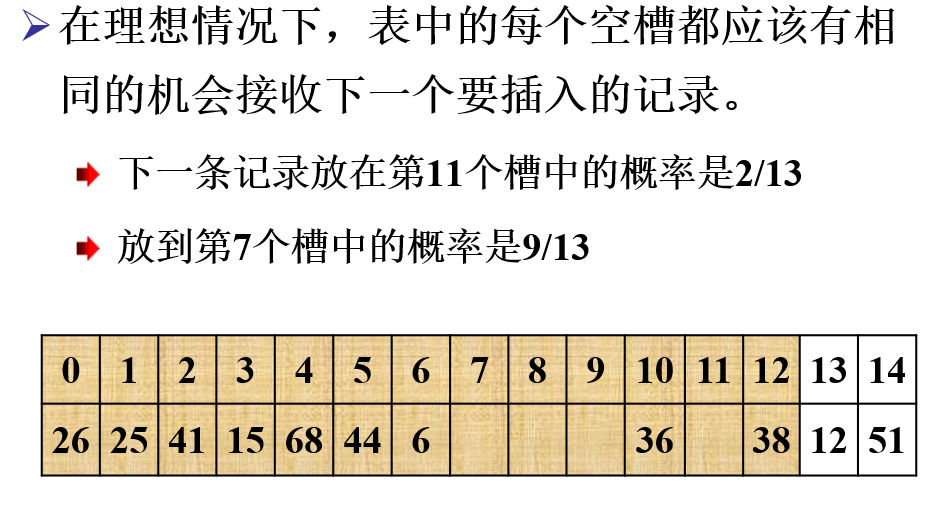
ASL 的计算: 成功看探查序列走了几步, 失败看探查序列走几步能到空位
1*. 改进线性探查
避免相邻位置的记录进入同一个探查序列, 但是其实没多大用, 间隔为 \(c\) 的还是会聚集
2. 二次探查
探查序列: \(1,-1,4,-4,...\)
3. 伪随机数序列探查
perm 是一个 1~M-1 的随机序列
虽然相邻基地址的探查序列还是相邻的, 但是不会出现线性探查导致的聚集

但是, 它们都无法解决二次聚集: 因关键码映射到相同基地址导致的聚集, 原因是它们的探查函数没有利用到关键码
4. 双散列探查法
利用第二个散列函数作为常数进行线性探查


\(h_2(key)\) 需与 \(M\) 互素, 才能使发生冲突的同义词地址均匀分布在整个表中.
10.3 闭散列算法实现¶

10.3.1 散列表的插入¶

10.3.2 散列表的检索¶

10.3.3 散列表的删除¶
有两点需要考虑:
- 删除记录不能影响后续检索
- 释放存储位置能为将来所用
只有开散列方法可以真正删除, 空间重用. 闭散列方法只能做标记, 不能真正删除, 空间未再次分配之前不可用. (因为探查序列检查到空后就会停止)
墓碑: 设置一特殊的标记位: 单元被占用, 空单元, 已删除.
被删除标记值称为墓碑.
插入的时候, 也不能遇到墓碑就停止, 而是要沿着探查序列下去直到空位置, 避免插入两个相同的关键码.
10.4 散列方法的效率分析¶

开散列:
相当于把 \(n\) 个数据均匀投入 \(m\) 个链中, 每个链的长度服从伯努利分布 \(B(n,p)\), \(p=1/m\)
当 \(n,m\to\infty\ 且\ np\to\alpha\) 时, \(B(n,p)\sim P(\alpha)\), 即参数为 \(\alpha\) 的泊松分布.
注: 参数为 \(\alpha\) 的泊松分布的分布列为 \(P(X=k)=\frac{\alpha^k e^{-\alpha}}{k!}\)
对于开散列的不成功检索:
-
对于长度为 \(0\) 的链, 检索一次比较是否为 NULL.
-
对于长度大于 \(0\) 的链, 比较链的长度.
注意这里比较次数的定义可能有所不同, 需具体分析.
对于任意一个不在散列中的数据, \(ASL\) 就是它投射到的链的期望比较次数
对于开散列的成功检索:
考虑一次检索的长度, 即为元素所在链在它之前的元素个数包括它自己.
对于其余的 \(n-1\) 个元素, 有 \(1/m\) 的概率和它在一个链, 在此基础上有 \(1/2\) 的概率在它前面, 于是期望长度就是 \(1+\frac{n-1}{2m}\approx1+\alpha/2\)
闭散列:
闭散列成功检索平均检索长度相当于负载因子从 \(0\) 变化到 \(\alpha\) 的时候不成功检索长度的平均, 因为成功检索相当于走一遍插入的过程, 于是可以用定积分描述:
(你可以试着计算一下看看是不是这样)
接下来考虑不成功检索, 对双散列法可以假设每次跳转到的位置是均匀分布的, 平均检索长度:
(\(\alpha\) 代表找到一个有位置的地方, 要继续找, \(1-\alpha\) 代表找到空位, 算法停止)
对于线性探查法. 跳转的位置不是均匀的, 与连续块的长度有关. 这部分推导需要更加高深的数学知识, 此处略去. 通过定性分析可以看出负载因子较大的时候线性探查由于聚集过多平均检索长度显著增加(平方项)
来自 Gemini 的直观解释:

可以想象成

临界值: \(\alpha=0.5\)
大量插删将降低检索效率, 可以定期重新组织散列表